请注意,本文编写于 53 天前,最后修改于 53 天前,其中某些信息可能已经过时。
目录
Transformer架构包含多种关键函数和组件,以下是其主要组成部分:
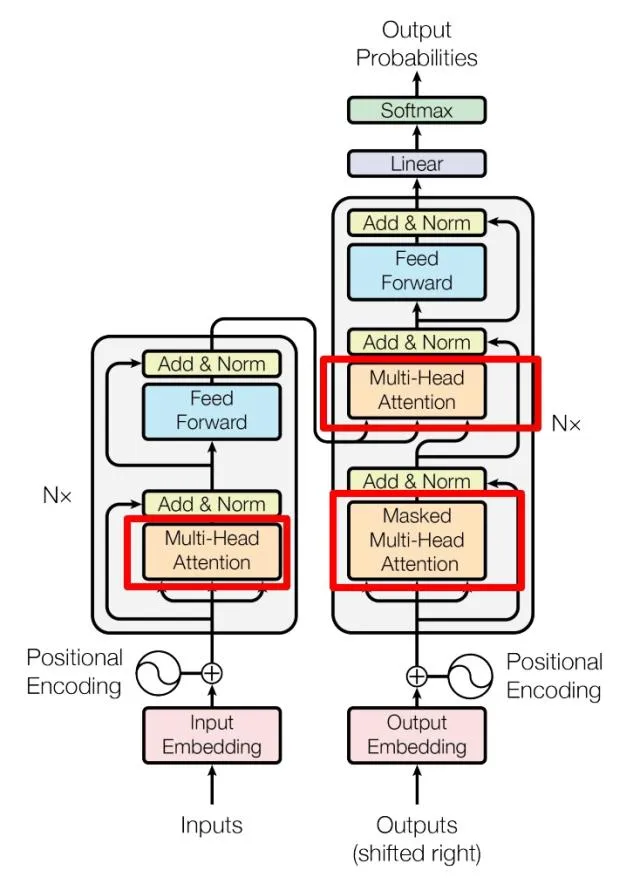
嵌入函数(Embedding Function)
- 作用:将输入的词或符号转换为向量表示。
- 类型:词嵌入(Word Embedding)、位置嵌入(Positional Embedding)。
- 位置编码:通过向嵌入向量添加位置信息,使模型能够处理序列的顺序。
自注意力函数(Self-Attention Function)
- 作用:计算序列中每个位置与其他所有位置的关系。
- 机制:通过查询(Query)、键(Key)和值(Value)的线性变换和点积计算注意力权重。
- 缩放点积注意力(Scaled Dot-Product Attention):对点积结果进行缩放,避免梯度消失。
前馈神经网络(Feed-Forward Neural Network)
- 作用:在每个编码器和解码器层中,对每个位置进行独立的非线性变换。
- 结构:包含两个线性变换,中间使用激活函数(如ReLU或GELU)。
编码器-解码器注意力函数(Encoder-Decoder Attention)
- 作用:在解码器层中,将解码器的查询与编码器的键和值进行注意力计算。
- 机制:类似于自注意力,但查询来自解码器,键和值来自编码器。
层归一化函数(Layer Normalization)
- 作用:在每个子层之后进行归一化,稳定训练过程,加速收敛。
- 位置:通常位于每个子层的输出和残差连接之后。
残差连接(Residual Connection)
- 作用:将子层的输入直接加到输出上,缓解深层网络的训练难度。
- 公式:。
位置编码函数(Positional Encoding Function)
- 作用:为输入序列添加位置信息,弥补自注意力机制无法捕捉顺序的缺陷。
- 方法:使用正弦和余弦函数生成位置编码向量,与嵌入向量相加。
损失函数(Loss Function)
- 作用:在训练过程中计算模型预测与真实标签之间的差异,指导模型优化。
- 常用损失函数:交叉熵损失(Cross Entropy Loss),适用于分类任务。
这些函数和组件共同构成了Transformer架构,使其在处理序列数据时表现出强大的能力。
目录